Coming soon:
Huge Numbers
Basic Books, April 2026

“Humanity has always been entranced by big numbers — the bigger the better. This fascinating exploration of the giants of the mathematical world is clear, informative, and immensely readable. Wonderful!”
– Ian Stewart
“A charming tour through the realm of the very, very, very numerous, from the ancient world through the distant future.”
– Jordan Ellenberg
“Elwes provides a phenomenal scenic tour of googology (the study of huge numbers), covering everything from ancient Mayan and Babylonian numeral systems to the scale of the universe to the dizzyingly fast-growing functions of mathematical logic. I wish I had written this book.”
– Scott Aaronson

Dr Richard Elwes is a writer and Associate Professor of Mathematics at the University of Leeds in the UK.
YouTube playlist of Richard on Numberphile.
Blog Archive
-
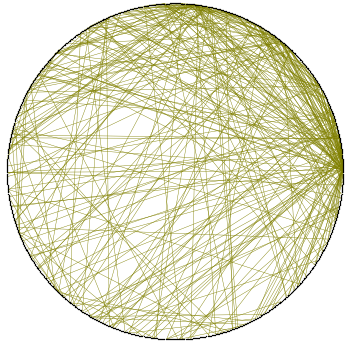
Random Graphs in Logic and Network Science
This is the video of a talk I gave at the British Logic Colloquium, on the topic of “Random Graphs in Logic and Network Science”, attempting to make some initial connections between two very…
-
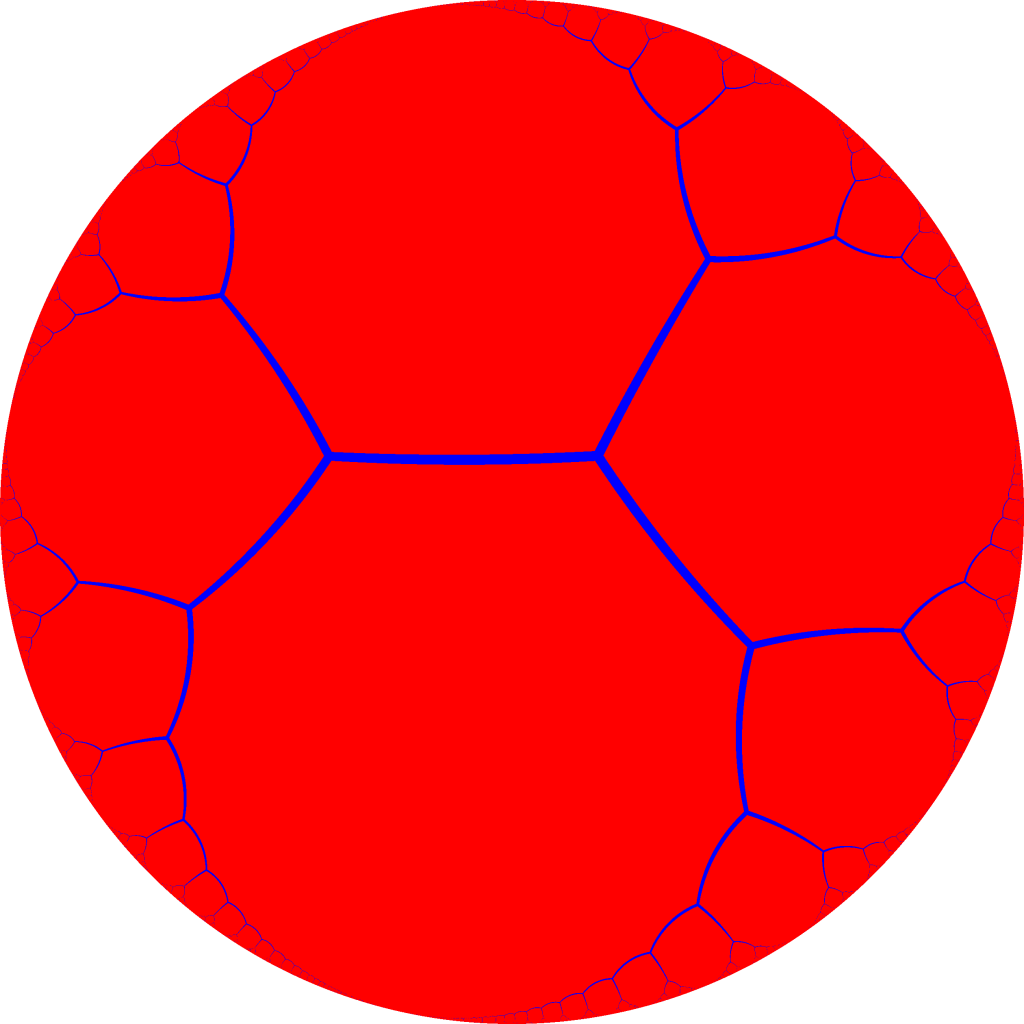
How Many Sides Does A Circle Have?
It’s a primary school homework question which causes disagreement among seasoned mathematicians. In order to find the correct answer, I called upon that most rigorous of scientific instruments, the Twitter poll: How many sides…
-

Magforming the Stewart Toroids
[This is a sequel to my previous post Magforming the Johnson Solids. Please see that for a disclaimer and (if you want to understand the words in this post) the geometrical background. If you…
-

Magforming the Johnson Solids
[Disclaimer: this is not a sponsored post or advert – it is a product purely of my own enthusiasm. But in the interests of full transparency, let me say one thing: for reasons you…
-

Book Review: Red Plenty by Francis Spufford
Imagine the benefits that could reaped if economic activity could be organised in a rational and scientific way, instead of abandoned to the chaos the marketplace! Imagine the efficiency gains there would be, with…
-

Barry Cooper, 1943-2015
Barry Cooper, who very sadly died on Monday, was a central member of the Leeds logic group since the 1960s. I joined that group as a graduate student in 2001, and since then have had the…
-

Learning to Learn from Babies
Yesterday, my twin sons turned one. I have spent an amazing number of hours over the last year watching them. I wondered if this experience might teach me something too, about how to learn. After…
-

The top 10 mathematical achievements of the last 5ish years, maybe
I have recently been going through my book Maths 1001 making updates for a forthcoming foreign edition (of which more in future). So I have been looking over mathematical developments since approximately 2009. Thus,…
-

Book Review: “What the Best College Teachers Do” by Ken Bain, 2004
I have a new post at The De Morgan Forum [link updated]. Review copied below: Open a typical book on the theory of pedagogy, and all too often one is confronted by a morass…
